
Calculating Sample Sizes For Human Factors Studies: What's The Magic Number?
By Seda Japp, Core Human Factors Inc.

Designing a research study can be a daunting process that calls for many considerations, including statistical power and sample size calculations. Although sample sizes for medical device usability testing are mostly defined by regulatory standards, it is important for manufacturers to understand the underlying principles, and to make sound decisions accordingly. This article provides a brief overview of statistical power and sample size within the context of usability.
Calculating Statistical Power
Statistical power is the likelihood that the study will detect an effect when there actually is an effect to be detected. As statistical power increases, the probability of making a type II error, also called a “false negative,” will decrease. That means, when a study is underpowered, it might fail to detect an effect that actually exists. In medical device usability testing, an underpowered study could lead to the conclusion that the test device is safe when it is not.
Smaller effect sizes would warrant a larger sample size for the same statistical power, because they are more difficult to detect. Although it is best practice to calculate sample size for any research study, it is harder to calculate the effect size (and, consequently, the sample size) for qualitative studies, compared to quantitative studies.
Quantitative usability studies mostly test the differences between certain quantifiable measures, such as time to completion, click-through-rate, or accuracy. Qualitative usability studies for medical devices aim to detect safety-related design problems by investigating the root causes of use errors.[i]
Use errors are a type of systematic fault, which makes it hard to calculate their frequency of occurrence until the conditions required for their occurrence emerge. As there is no consensus on how to estimate their probability, international standards suggest considering them on the basis of severity alone.[ii] Regulatory agencies also discourage manufacturers from doing sample size calculations for traditional qualitative usability studies.
Calculating Sample Size
The international standard 62366-2[iii] states that there are diminishing returns on detecting new usability problems when sample size goes beyond 10 for each distinct user group. This is based on calculations determining cumulative probability of detecting a usability problem:
R = 1 - (1 - P)n
where
R = cumulative probability of detecting a usability problem,
P = probability of a single test showing a usability problem, and
n = number of participants.
Table 1 and Fig. 1 depict the cumulative probability of detecting a usability problem at each probability and sample size.
Table 1 — Cumulative probability of detecting a usability problem at each probability and sample size (per 62366-2)
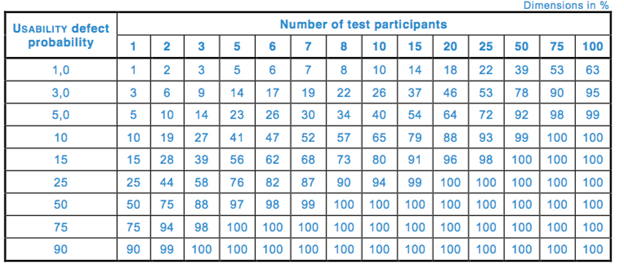
Fig. 1 — Proportion of problems uncovered as a function of number of subjects in the evaluation (62366-2)
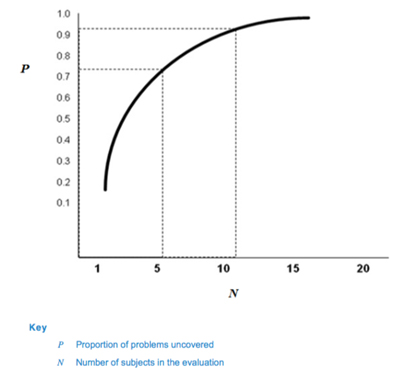
Based on this calculation, 62366-2 suggests that many usability problems can be discovered with sample sizes in the range of five to eight participants, which has been the industry standard in formative studies for many years.
For validation (or summative) testing, on the other hand, 62366-2 indicates that 15 participants per distinct user group (the minimum number recommended by the FDA[iv]) is likely to meet the need. The magical number ‘15’ for validation testing is based on a study conducted by Faulkner (2003)[v] where the author collected empirical data from a sample of 60 individuals who had various levels of experience with computers and the software being tested. The study results indicated that a sample of 15 people was sufficient to find a minimum of 90 percent — and an average of 97 percent — of all problems with the software being tested.
It is worth noting that the probability of detecting use errors could significantly differ depending on the complexity of the product and types of use errors (e.g., use errors with smaller probability of occurrence might require a larger sample size to be detected). The FDA also notes that the published estimates of the sample size required for usability studies are based on assumptions regarding a fixed probability of encountering a problem, equal likelihood for each participant to encounter each problem, and the independence of the problems (that is, encountering one use error will not increase the likelihood of finding another use error).
Such assumptions are necessary to determine a specific sample size. However, many uncontrolled variables and interrelated interactions within the human-device interaction system can render these assumptions faulty. Thus, although a 15-participant minimum is suggested, a larger sample size might be beneficial if a thorough analysis of the product, or previous knowledge about the product and/or similar systems, indicates a need.
Although sample size calculations are not required by the FDA or 62366 for medical device usability testing, smaller sample sizes make it less likely that use errors with a lower probability of occurrence will be detected (Table 1). Therefore, it is still debated whether usability tests, the way they are conducted right now, inevitably detect only the most frequently occurring use errors.
All that said, there exist other types of use-related studies, conducted on medical devices, that might benefit from a sound sample size calculation. Those include, for example, comparative studies — where prototypes are tested against each other — and quantitative metrics, wherein factors such as time to completion, error rate, likeability, ease of use, or other dimensions of interest are collected and then used by the manufacturer to make design decisions.
To calculate the sample size, an initial pilot study can be conducted on a smaller sample. Based on the effect size yielded by the pilot study, the sample size needed for a power of 80-95 percent can be calculated. If it is not possible to conduct a pilot study first, the effect size also can be estimated based on the results of previous studies on similar devices.
Sample size calculations also play a pivotal role in comparative studies of combination products, with the goal of proving a new generic device's non-inferiority compared to a reference listed drug. The FDA[vi] recommends a within-subject design (i.e., testing both devices on the same participants), which requires a smaller sample size compared to a between-subject design (i.e., testing each device on a different set of users) to achieve the same statistical power.
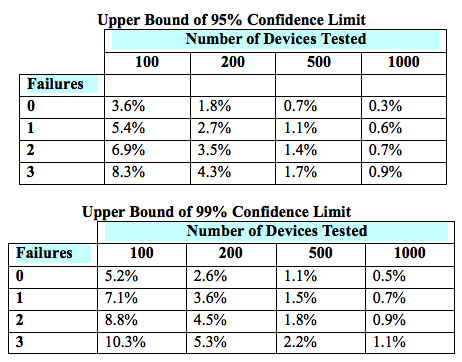
The sample size of a paired design for non-inferiority depends on the acceptable margin of error between the two devices, the within-subject correlation, the underlying use error rates, the desired statistical power, and the allowable type I error probability (i.e., the probability of a “false positive”). The FDA provides lists of simulated sample sizes (Table 2) needed for different levels of power, within-subject correlation, and use error probability. However, it also encourages each manufacturer to determine the appropriate metrics for its own products.
Table 2 — Simulated sample sizes needed to detect 0-3 failures with 95-percent confidence (top) and 99-percent confidence (bottom), per the FDA’s guidance6
Conclusions
It is important to remember that usability studies test a sample from the population. While best efforts should be applied to ensuring the test sample is as representative of the intended user population as possible, 100-percent match is unlikely. In real life, some users may have a completely different mental model than participants tested in the usability study, and different use errors might emerge. Thus, it is pivotal to have an appropriate sample size to detect most of the use-related issues.
Therefore, it is worthwhile for manufacturers and usability researchers to take time to think about the unique nature of each product and study, and then decide on the sample size accordingly to maximize detection of use-related issues.
About the Author
Seda Japp is an associate at Core Human Factors, Inc. She majored in Computer Engineering and received MSc. and PhD. degrees in Cognitive Neuroscience from Max Planck Institute and Humboldt University of Berlin in Germany. She also worked at the University of Pennsylvania as a postdoctoral researcher where she investigated the neural and behavioral basis of depression and anxiety. She has extensive experience in medical devices like MRI, EEG and TMS that are used both for research and treatment purposes. The combination of her expertise in engineering, medical devices and human behavior led her to a career in Usability of Medical Devices.
[i] Use error is a user action or lack of action that leads to a different result than that intended by the manufacturer or expected by the user (IEC TR 62366-1: Medical Devices - Part 1: Application of usability engineering to medical devices)
[ii] ANSI/AAMI/ISO 14971: 2007 - Medical devices - Application of risk management to medical devices
[iii] IEC TR 62366-2: Medical devices - Part 2: Guidance on the application of usability engineering to medical devices
[iv] Applying Human Factors and Usability Engineering to Medical Devices, Guidance for Industry and Food and Drug Administration Staff, February 3, 2016 FDA
[v] Faulkner L., Beyond the five-user assumption: Benefits of increased sample size in usability testing, Behavior Research Methods, Instruments, and Computers 2003, 35 (3), 379-383
[vi] Comparative Analyses and Related Comparative Use Human Factors Studies for a Drug-Device Combination Product Submitted in an ANDA: Draft Guidance for Industry